
Wordsmith is an AI assistant for in-house legal teams, reviewing legal docs, drafting emails, and generating contracts using LLMs powered by the customer’s knowledge base. Unlike other legal AI tools, Wordsmith has deep domain knowledge from leading law firms and is easy to install and use. It integrates seamlessly into email and messaging systems to automatically draft responses for the legal team, mimicking what it’s like to work with another person on the team.
Having experienced an exponential growth in LLM-powered features over the past few months, WordSmith’s engineering team needed better visibility into LLM performance and interactions. LangSmith has been vital to understanding what’s happening in production and measuring experiment impact on key parameters. Below, we’ll walk through how LangSmith has provided value at each stage of the product development life cycle.
Prototyping & Development: Wrangling complexity through hierarchical tracing
Wordsmith’s first feature was a configurable RAG pipeline for Slack. It has now evolved to support complex multistage inferences over a wide variety of data sources and objectives. Wordsmith ingests Slack messages, Zendesk tickets, pull requests, and legal documents, delivering accurate results over a heterogeneous set of domains and NLP tasks. Beyond just getting the right results, their team needed to optimize for cost and latency using LLMs from OpenAI, Anthropic, Google, and Mistral.
LangSmith has become crucial to Wordsmith's growth, enabling engineers to work quickly and confidently. With its foundational value-add as a tracing service, LangSmith helps the Wordsmith team transparently assess what the LLM is receiving and producing at each step of their complex multi-stage inference chains. The hierarchical organization of inferences lets them quickly iterate during the development cycle, far faster than when they relied solely on Cloudwatch logs for debugging.
Consider the following snapshot of an agentic workflow in which GPT-4 crafts a bad Dynamo query:
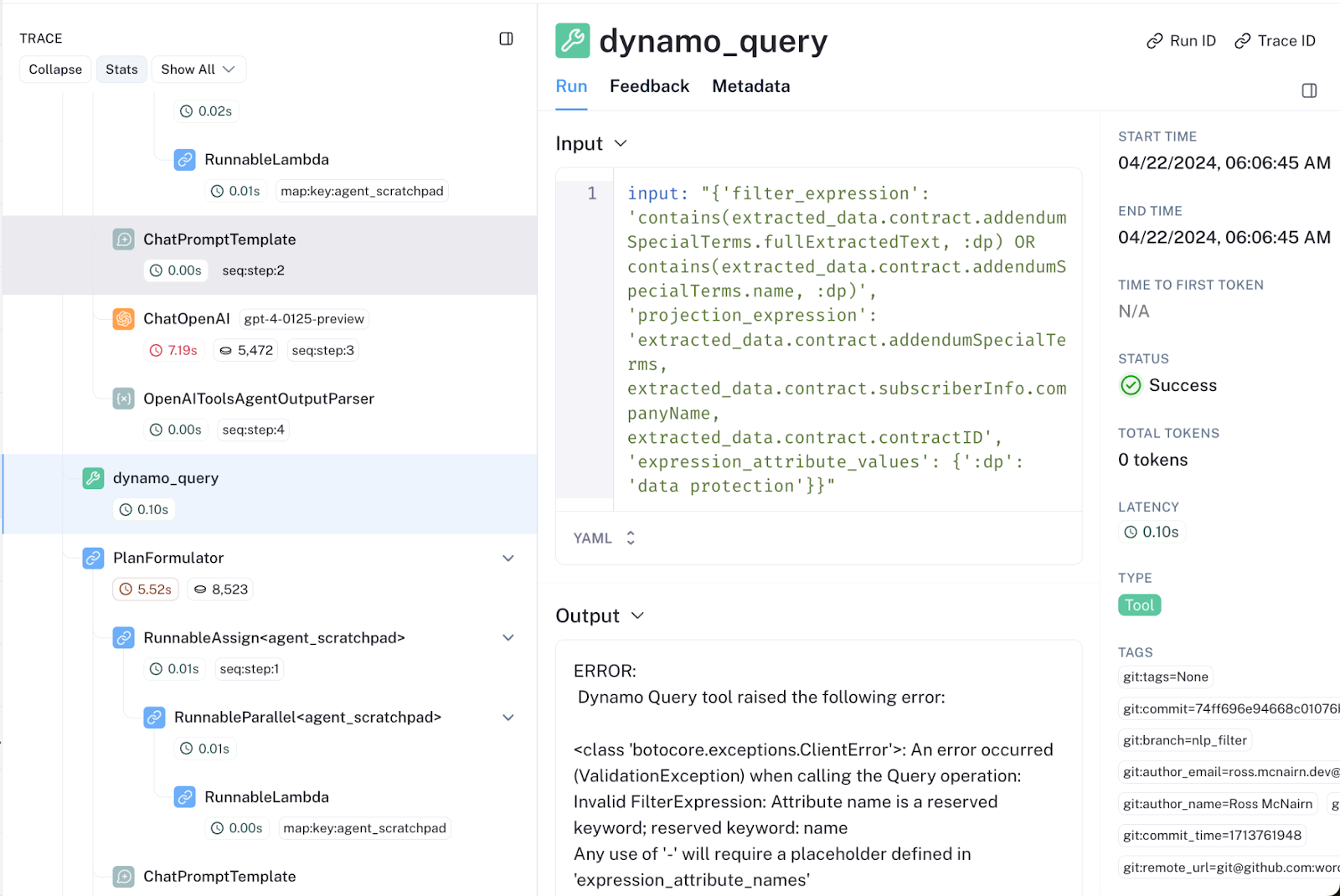
These workflows can contain up to 100 nested inferences, making it time-consuming and painful to sift through general logs to find the root cause of an errant response. With LangSmith’s out-of-the-box tracing interface, diagnosing poor performance at an intermediate step is seamless, enabling much faster feature development.
Performance Measurement: Establishing baselines with LangSmith datasets
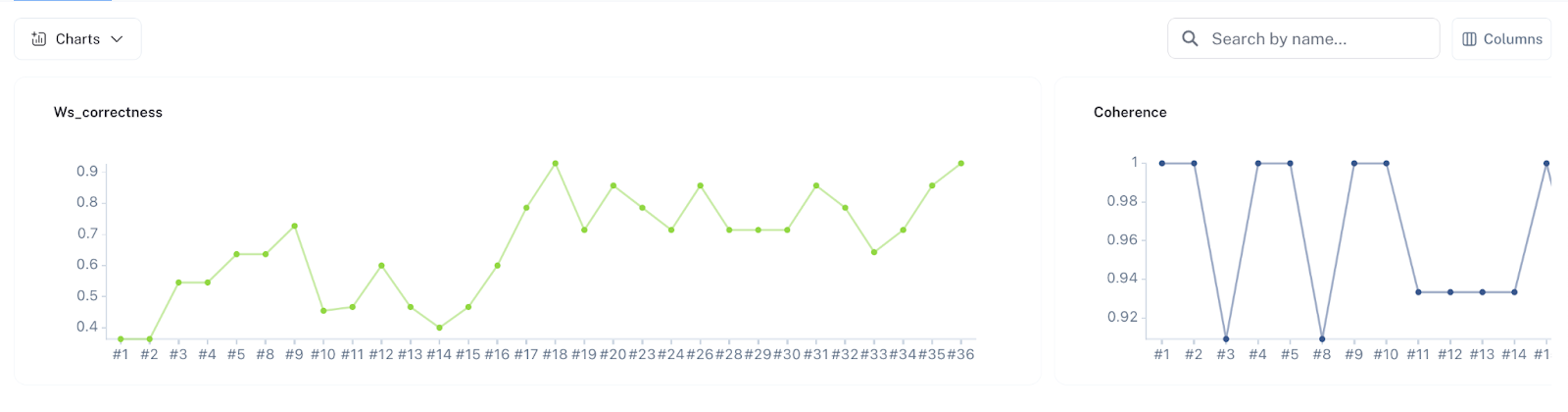
Reproducible measurement helps differentiate a promising GenAI demo from a production-ready product. Using LangSmith, Wordsmith has published a variety of evaluation sets for various tasks like RAG, agentic workloads, attribute extractions, and even XML-based changeset targeting — facilitating their deployment to production.
These static evaluation sets provide the following key benefits:
- Eval sets crystalize the requirements for Wordsmith’s feature. By forcing the team to write a set of correct questions and answers, they set clear expectations and requirements for the LLM.
- Eval sets enable the engineering team to iterate quickly and with confidence. For example, when Claude 3.5 was released, the Wordsmith team was able to compare its performance to GPT-4o within an hour and release it to production the same day. Without well-defined evaluation sets, they would have to rely on ad-hoc queries, lacking a standard baseline to confidently assess if a proposed change improved user outcomes.
- Eval sets let the Wordsmith team optimize on cost and latency with accuracy as the key constraint. Task complexities are not uniform, and using faster and cheaper models where possible has reduced cost on particular tasks by up to 10x. Similar to (2), this optimization would be time-consuming and error-prone without a predefined set of evaluation criteria.
Operational Monitoring: Rapid debugging via LangSmith filters
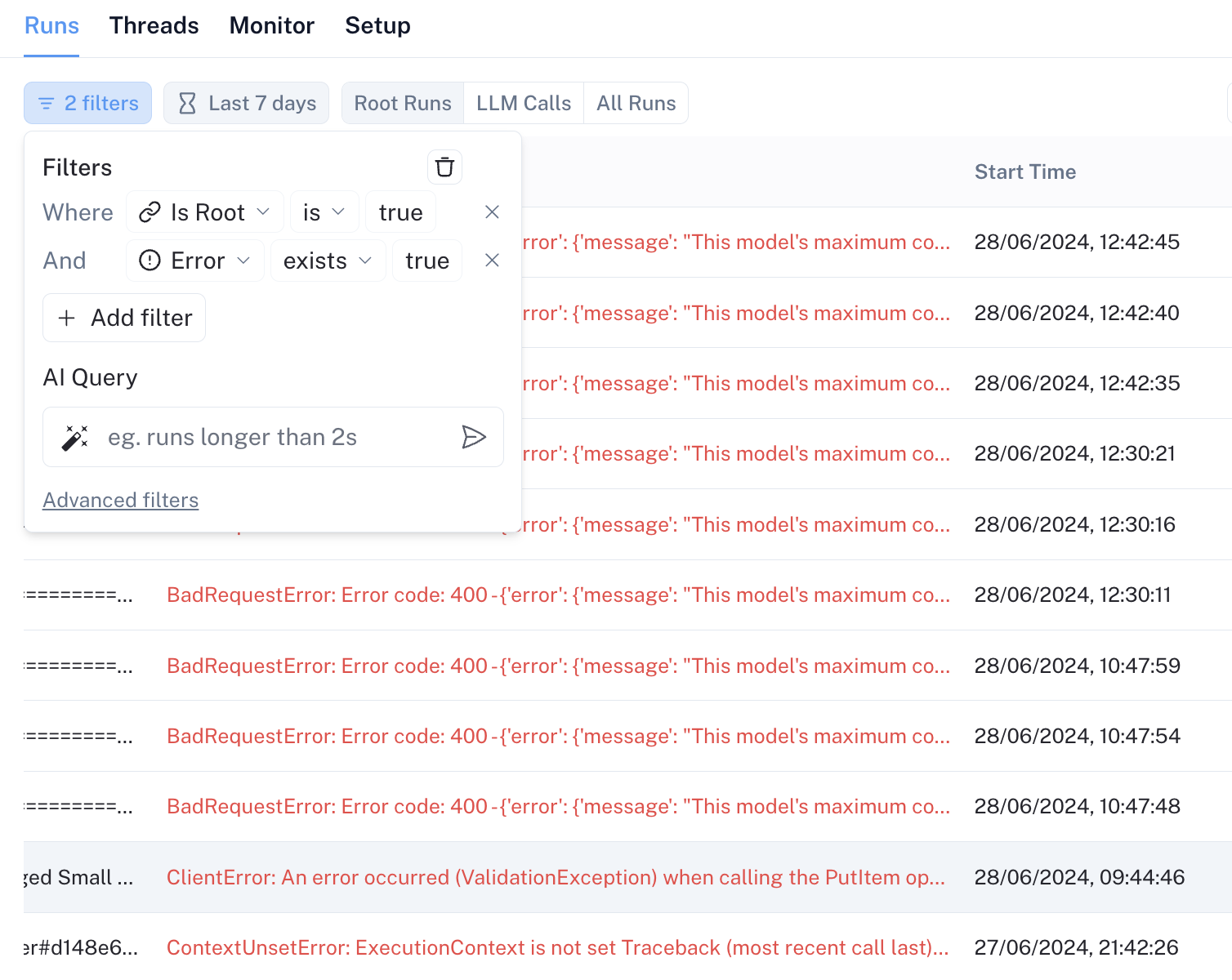
The same visibility features that make LangSmith ideal for development also make it a core part of Wordsmith’s online monitoring suite. The team can immediately link a production error to its LangSmith trace, reducing time to debug an inference from minutes to seconds by simply following a LangSmith URL instead of perusing logs.
LangSmith’s indexed queries also make it easy to isolate production errors related to inference issues:
Online Experimentation: Enabling experiment analyses via tags
Wordsmith uses Statsig as their feature flag / experiment exposure library. Leveraging LangSmith tags, it’s simple to map each exposure to the appropriate tag in LangSmith for simplified experiment analyses.
A few lines of code are all it takes for us to associate each experiment exposure to an appropriate LangSmith tag:
In LangSmith, these exposures are queryable via tags, allowing for seamless analysis and comparison between experiment groups:
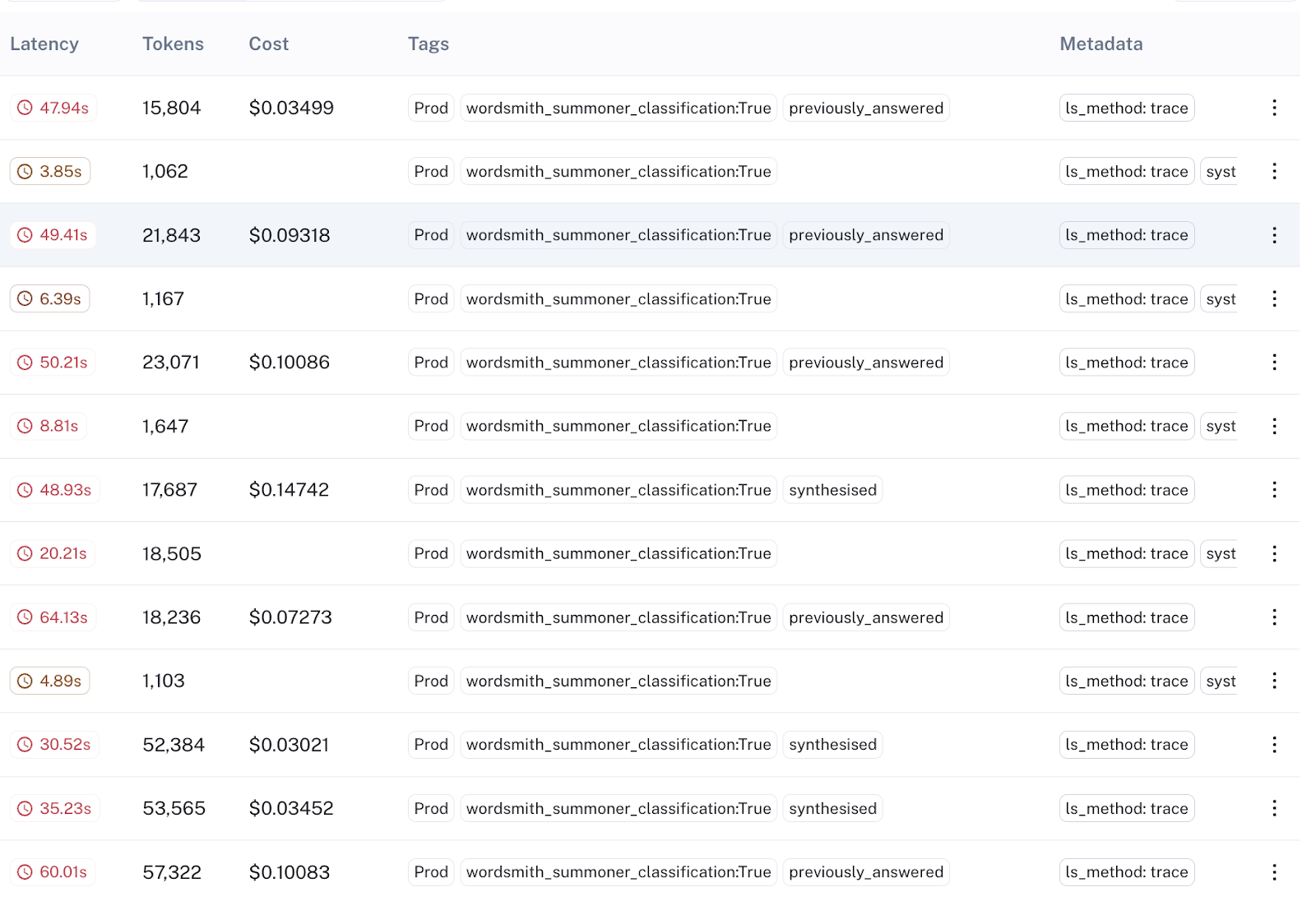
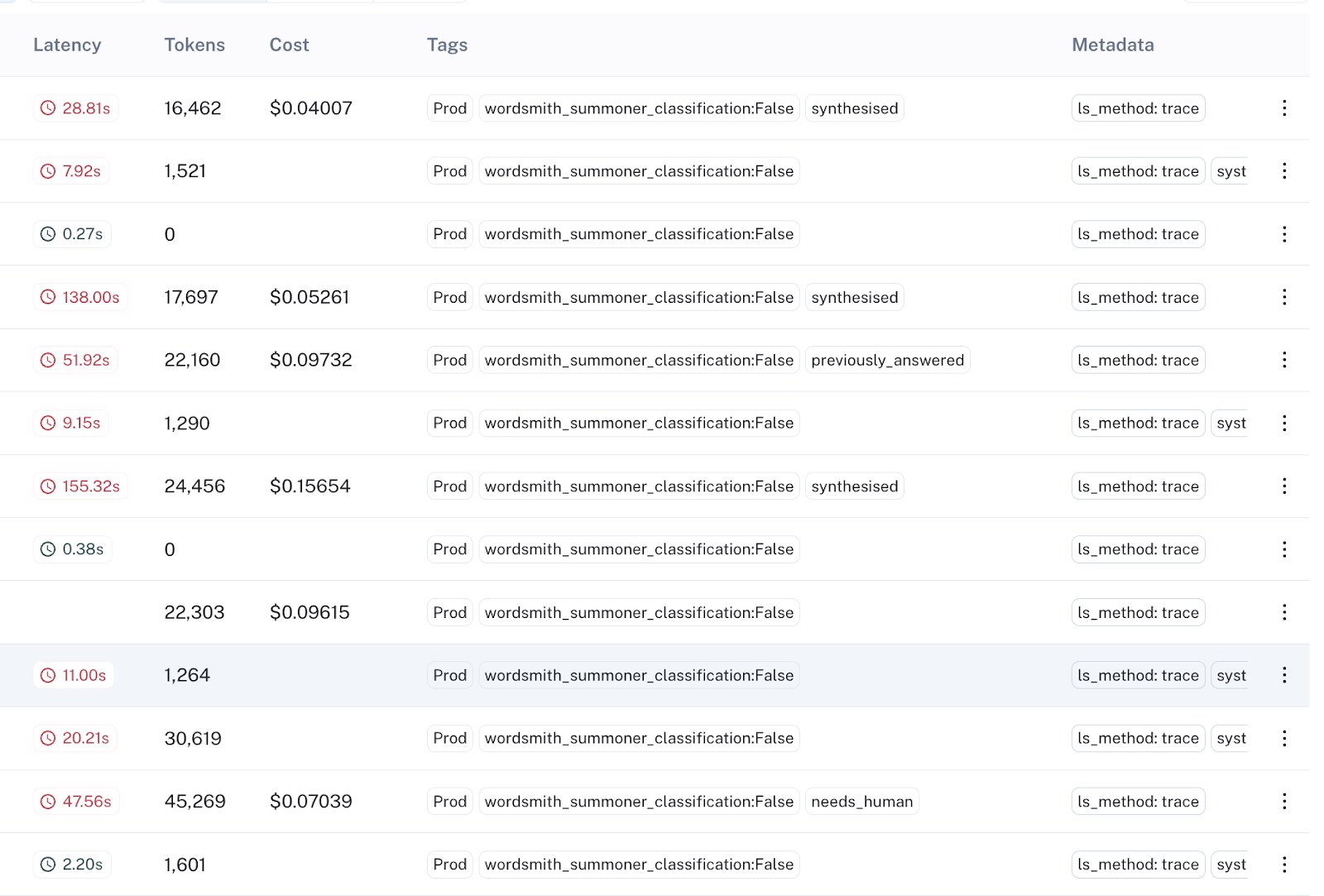
Using basic filters, they can fetch all experiment exposures in LangSmith, save them to a new dataset, and export the dataset for downstream analysis. LangSmith thus plays a crucial role in the Wordsmith product’s iterative experimentation and improvement.
What’s Next: Customer-specific hyperparameter optimization
At each stage of the product life cycle, LangSmith has enhanced the Wordsmith team’s speed and visibility into the quality of their product. Moving forward, they plan to integrate LangSmith even more deeply into the product life cycle and tackle more complex optimization challenges.
Wordsmith’s RAG pipelines contain a broad and ever-increasing set of parameters that govern how the pipelines work. These include embedding models, chunk sizes, ranking and re-ranking configurations, etc. By mapping these hyperparameters to LangSmith tag (using a similar technique to their online experimentation), Wordsmith aims to create online datasets to optimize these parameters for each customer and use case. As datasets grow, they envision a world in which each customer’s RAG experience is automatically optimized based on their datasets and query patterns.